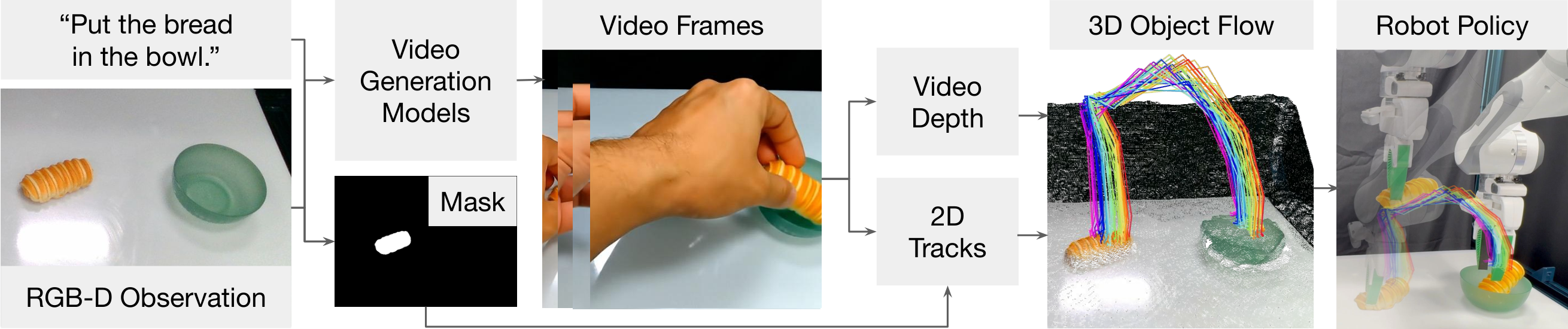
Generative video modeling has emerged as a
compelling tool to zero-shot reason about plausible physical
interactions for open-world manipulation. Yet, it remains a
challenge to translate such human-led motions into the low-level
actions demanded by robotic systems. We observe that given an
initial image and task instruction, these models excel at synthesizing sensible object motions. Thus, we introduce Dream2Flow,
a framework that bridges video generation and robotic control
through 3D object flow as an intermediate representation. Our
method reconstructs 3D object motions from generated videos
and formulates manipulation as object trajectory tracking. By
separating the state changes from the actuators that realize
those changes, Dream2Flow overcomes the embodiment gap
and enables zero-shot guidance from pre-trained video models
to manipulate objects of diverse categories—including rigid,
articulated, deformable, and granular. Through trajectory optimization or reinforcement learning, Dream2Flow converts reconstructed 3D object flow into executable low-level commands
without task-specific demonstrations. Simulation and real-world
experiments highlight 3D object flow as a general and scalable
interface for adapting video generation models to open-world
robotic manipulation.